Back in August of last year Ashok Elluswamy, Tesla’s Director of Autopilot Software, gave an in-depth presentation on Autopilot & FSD Beta. I found this presentation extremely informative and took some notes that I wanted to share with you all. You can find the full presentation here.
- Current hardware configuration
- 144 TOPS of compute onboard
- 360 FOV
- 36 FPS
- No radar or ultrasonics used in SW
- No HD maps
- “Classical” drivable space

- Image-space segmentation method, pretty standard in industry for mapping out drivable space
- Every pixel is mapped out whether it is drivable or not drivable, hope is the planning stack can use this information to map a route
- These predictions are in image space in UV values
- In order to navigate the world in 3D the car needs to have predictions in 3D space so it can build physical models of interaction and handle driving tasks
- Going from image space to 3D space when doing pixel segmentation can produce unnecessary artifacts or noise
- Few pixels at horizon can have huge influence depending on how Tesla transfers from image space to 3D space (cannot have this)
- Not a fundamental limitation this is just a limitation of this representation
- Does not provide full 3D structure of the scene, very much 2D
- Dense Depth

- A different way to model general obstacles is dense depth
- In this task you can make the network predict depth on a per pixel basis, every pixel produces a depth value
- Even though the depth maps look pretty when visualized in color space, the challenge comes when you use depth to un-project the rays into 3D points & visualize those 3D point clouds
- Close up they look fine and detailed however at distance they lack the appropriate detail resolution to make intelligent predictions
- Inconsistent results locally so walls for example wouldn’t be straight lines (curving, etc.)
- Things close to the horizon are represented by very points so creates challenge for planning stack when planning around obstacles
- Depth maps are produced on the image plane on a per camera basis which makes it challenging to produce a single, consistent 3D space around the car
- Since depth maps are typically modeled as regression targets it is hard to predict through occlusions and also at boundaries due to the properties of the networks can smoothly change (ex vehicle to the background) which creates unnecessary artifacts / noise in 3D space
- Occupancy Networks
- Image-space segmentation & dense depth maps are not sufficient for obstacle planning because 2D, do not work through occlusions, worse at distance
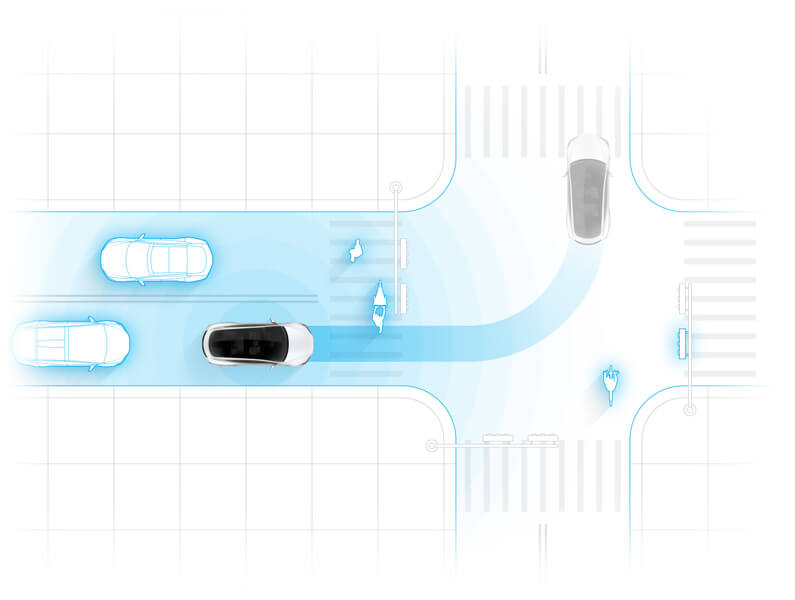
- Occupancy networks take in all the 8 camera streams of input and produces a single, consistent volumetric occupancy around the car
- Voxel - A point in 3D space
- Every voxel or location around car the network produces whether the voxel is occupied or not
- Produces a probability of the voxel being occupied or not
- Takes all 8 cameras and produces a single volumetric output, there is no stitching of independent predictions to produce this
- The networks do all the internal sensor fusion to produce the single consistent output space
- These networks produce both static occupancy (trees, walls, etc.) as well as dynamic occupancy (vehicles, debris, etc.)
- Since the output space is directly in 3D, we can predict things through occlusions (ex. presence of curb even when a car is in the way)
- This approach is extremely memory and compute efficient because it allocates resolution where it really matters
- Almost uniform resolution throughout the volume that is relevant for driving
- Runs in 10ms on current FSD hardware, runs at 100Hz which is much faster than what the cameras run at
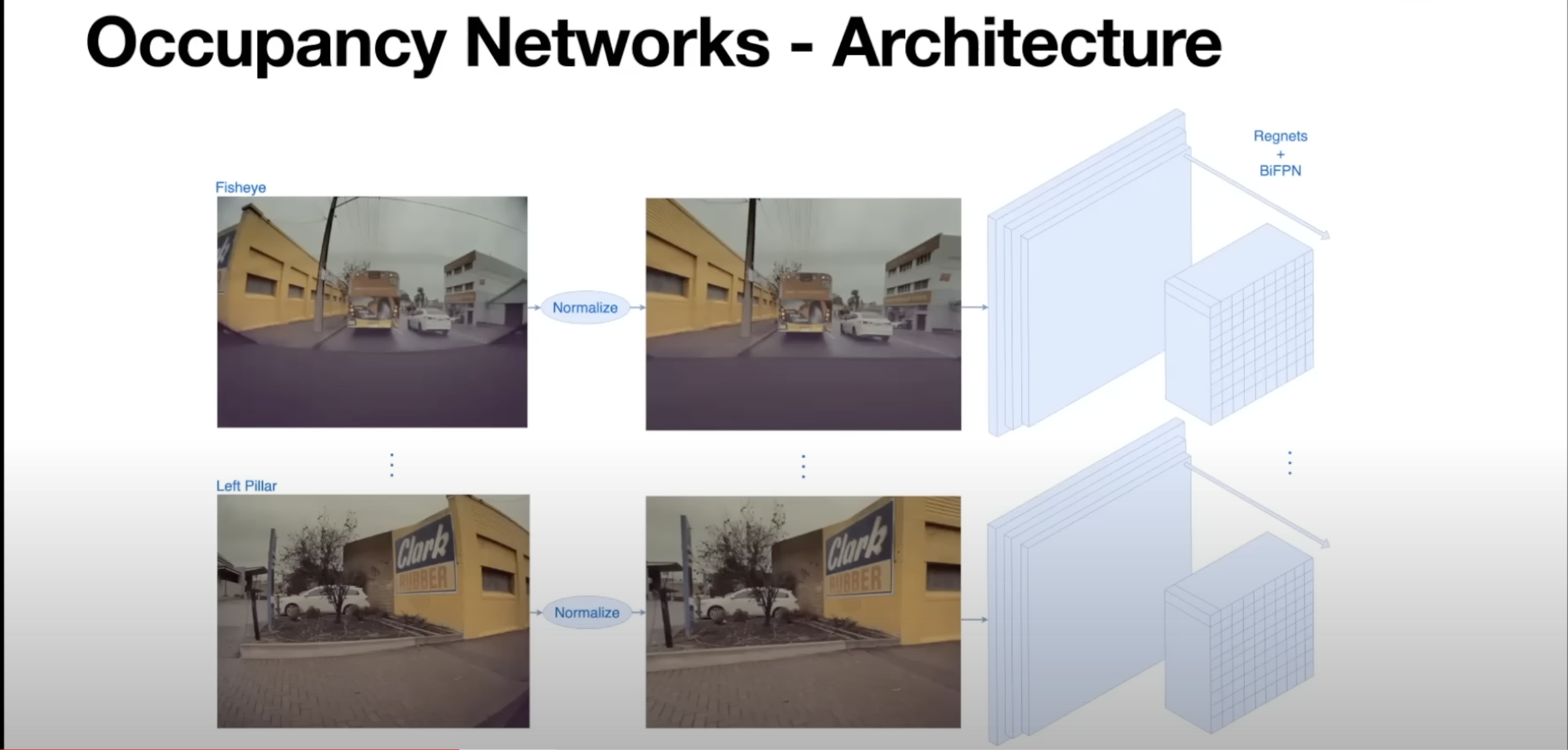
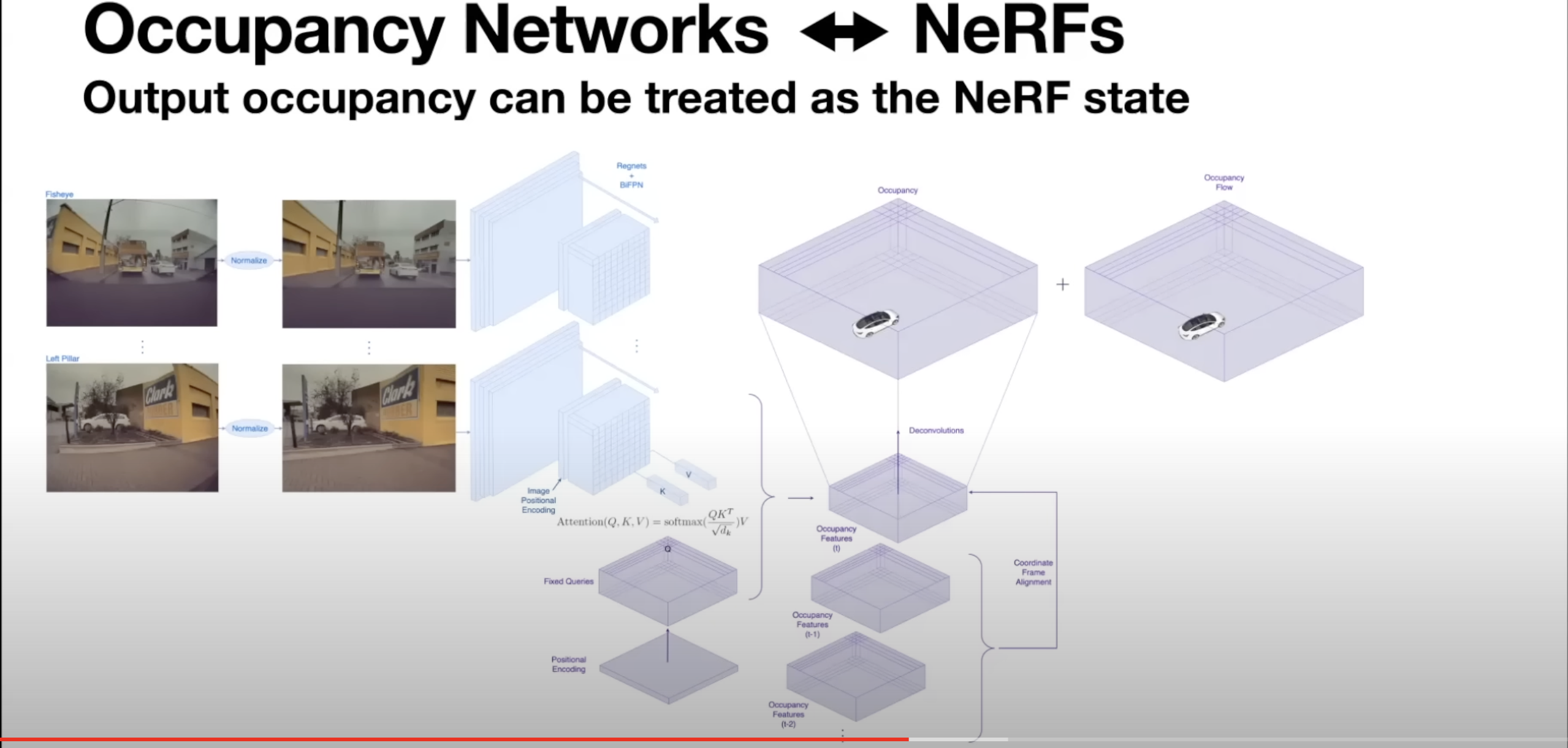
- High level network architecture
- Images captured by camera are normalized
- Images are then fed into state of the art of image backbone architectures (Regnets & BiFPNs) to extract image features (can be swapped w/ state of the art architecture such as cbpr2022)
- These backbones now produce high dimensional features in image space
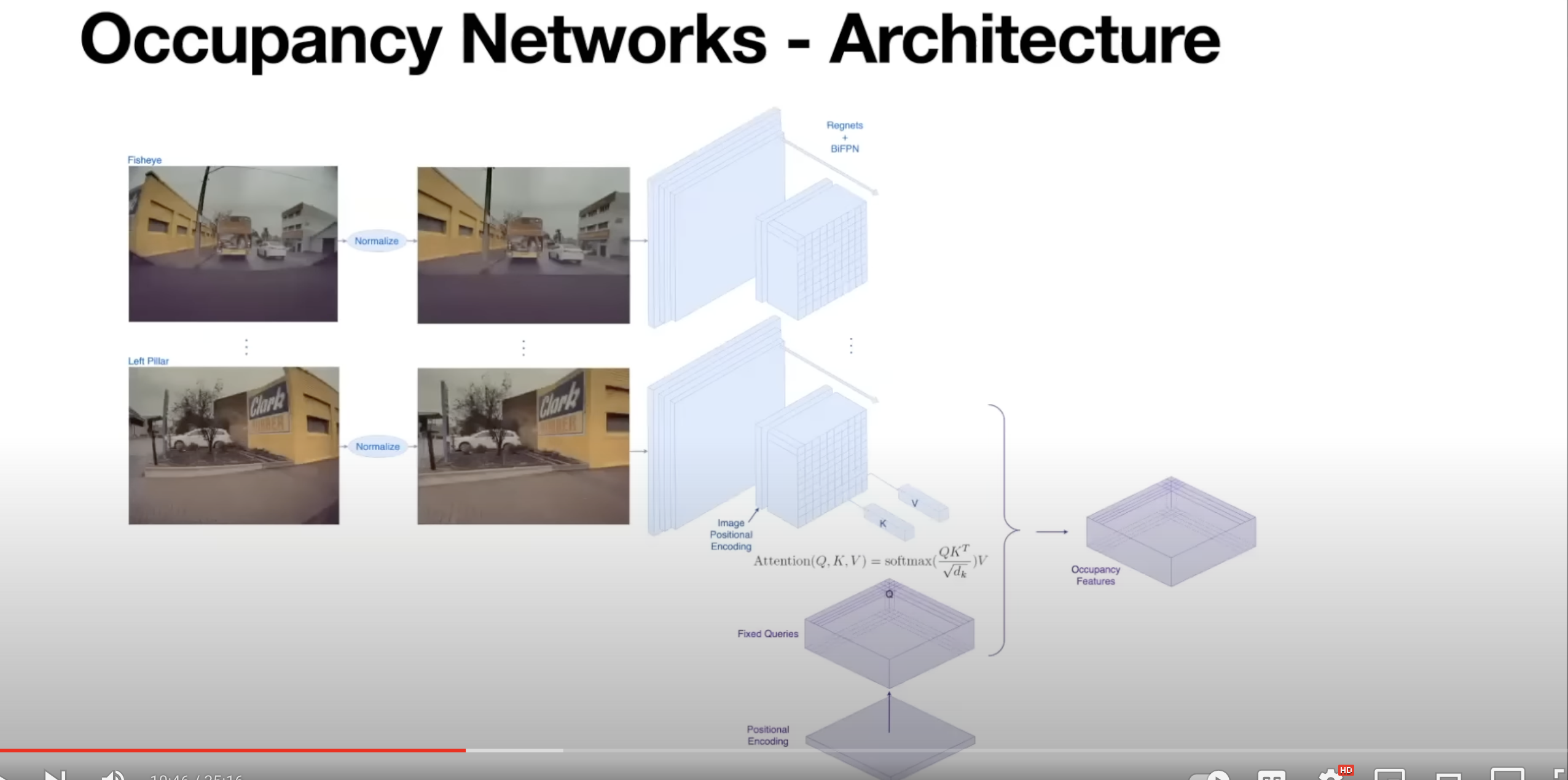
- We want occupancy to be in 3D so how is that done?
- Query-based attention to produce 3D occupancy features
- Queries 3D point for whether it is occupied or not
- Take 3D positional encoding then mapping into fixed queries which then attend to every image space feature
- Positional embedding in the image space so now these 3D queries attend to image space queries of all image streams
- Then produce 3D occupancy features
- Since these are high dimensional features it is hard to do this directly at every point in 3D space
- The workaround is to produce these high dimensional features at low resolution and use typical upscaling techniques like deconvolutions to efficiently produce denser high resolution occupancy
- Initially Tesla was only planning to use occupancy networks on static objects (walls, trees, etc.)
- They already had networks that handled moving objects
- These networks would then produce the kinematics of the vehicle such as depth, velocity, acceleration, jerk, etc.

- Turns out having a explicitly defined ontology (metaphysics dealing with the nature of being) tree can be pretty tricky to produce
- In the example above, a pickup truck that looks like a fence is easy to recognize when it is moving but when it is stopped it can result in the car getting confused (looks like a fence)

- This example is even trickier w/ pedestrians
- Impossible to fight so the solution to this problem is to produce both moving and static obstacles in the same framework, this way things can’t slip through the cracks between moving & stationary (there is no such things as stationary objects)
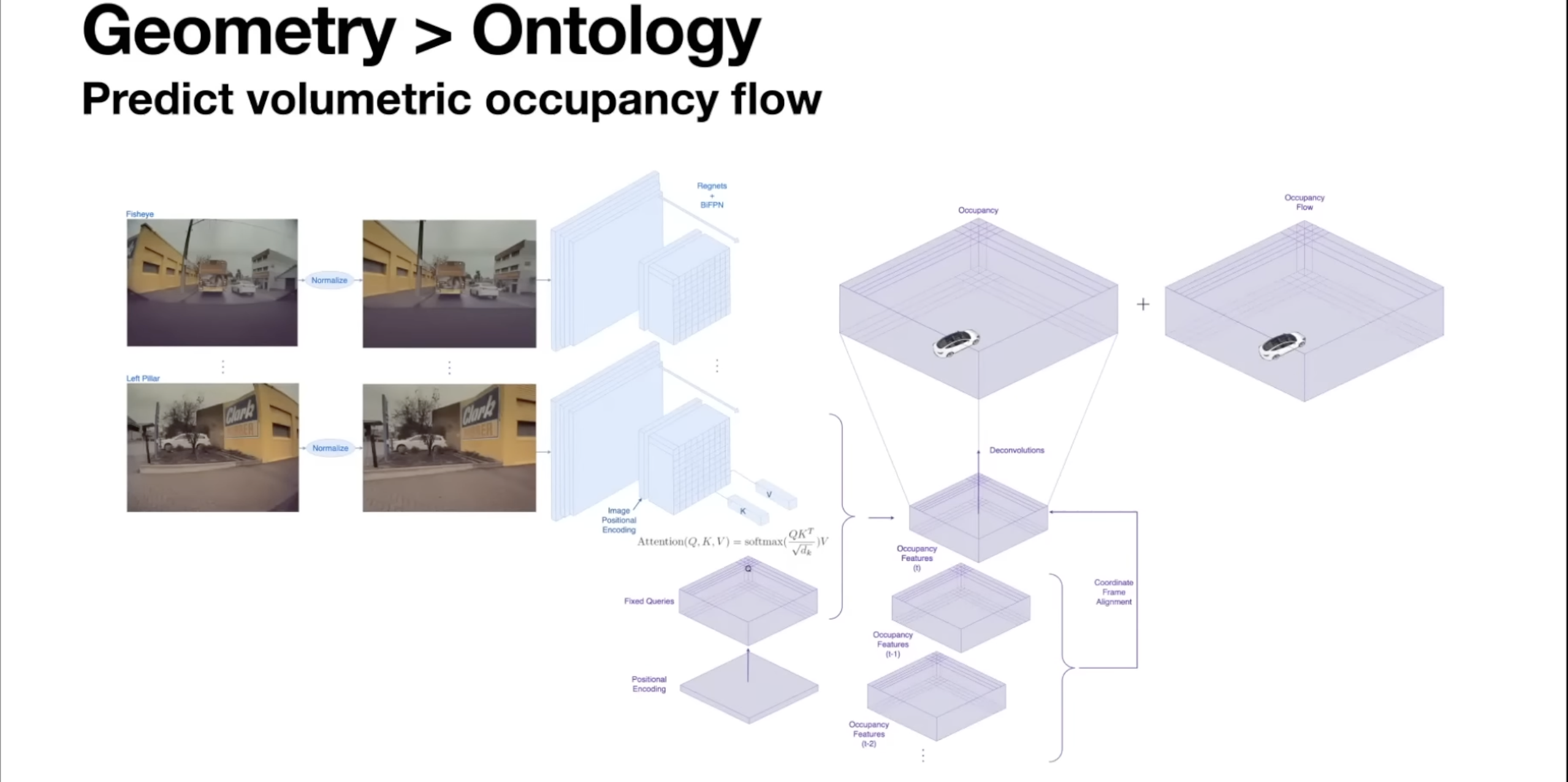
- Occupancy networks produce everything that’s occupied in the scene
- Instantaneous occupancy is not sufficient at speed especially when following a vehicle on highway, we don’t want to assume that occupied voxels are at 0 velocity and then just slow down because you want to slow down to avoid stationary obstacles, so we instead want to know future occupancy (how occupancy will change)
- ex. Allows us to know the vehicle ahead will move away by the time the ego vehicle reaches that location
- In addition to occupancy we predict occupancy flow
- Occupancy flow - Can be the first derivative of occupancy or time or can also high derivatives that can give more precise control
- To produce occupancy flow we take in multiple time steps as input so we take all the diff occupancy features from some buffer of time, align all them into a single coordinate frame, use same upsample techniques to produce both of the occupancy and occupancy flow
- Provides robust protection against all kinds of obstacles
- This knows there are moving things even if it doesn’t know what the obstacles are
- Provides nice protection against these kinds of classification dilemmas
- Regardless of what is occupying the volume space the car knows something is there and moving at a specific rate of speed
- Special vehicles can have strange protrusions that can be hard to model using traditional techniques

- Can also use geometric information to reason about occlusion
- Car is aware of occlusions and therefore can handle ways to remove occlusions and see past them (ex. creep forward)
- Neural Radiance Fields (NeRFs)
- Tesla team thinks of occupancy networks as extension of neural radiance fields
- Neural radiance fields - Try to reconstruct the scene from multi-view images

- Tesla can take a trip from any car in fleet to produce accurate camera courses across time and then run state of the art NeRF models to produce really good 3D reconstruction by differentiability rendering images from the 3D state
- Initial implementation from nerf paper used a single NN to represent full 3D scene
- More recently other works such as plano cells that use voxel-based representations to do this
- Also can extend to have both voxels of tiny MLPs or other continuous representation to interpolate the probability to produce these differentiability rendered images

- One problem with running NeRFs on raw images because of image artifacts
- High level descriptors can be used to combat things like glare because RGB can be extremely noisy
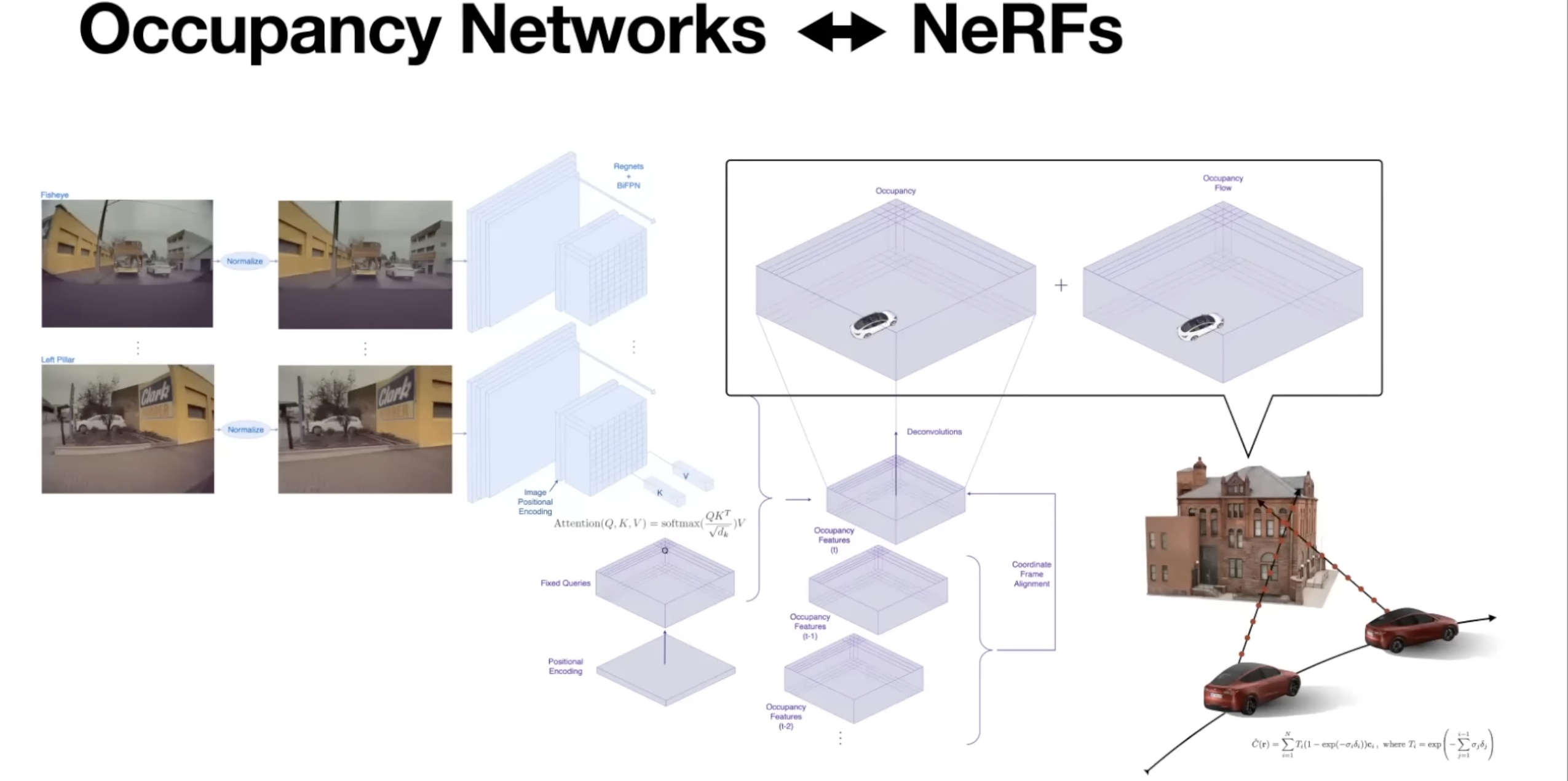
- Goal is to use this super vision for occupancy networks
- NeRFs can be used as a loss function to occupancy networks
- Full NeRF optimization cannot be run since occupancy networks need to produce occupancy in a few shots
- Can have a reduced NeRF optimization run in the car all the time in background making sure the occupancy that it produces is explaining all the sensor observation receives at runtime
- In addition it can be stacked on top at training time to produce good supervision for these networks
- Collision avoidance

- Autopilot saves humans from colliding like in the example above where the driver confused accelerator for brake and almost pinched his wife in between his car and another
- 40 accelerator misapplications saved every day
- Another example shown was a car nearly going into a river
- Another example shows the car stopping short of an old lady as the car was parking

- More collisions remain to be prevented like the one where somebody backed into their garage
- Driver was driving manually
- Driver unintentionally pressed accelerator to 100%
- First in forward direction, then in reverse
- AP saved the forward crash but wasn’t able to avoid the one in reverse
- For a self driving car to be useful, it needs to be:
- Safe
- Comfortable
- Reasonably fast
- Takes intelligence to drive in all 3

- Green - Car is safe when put in this position
- Red - Car when put in configuration is on track for a collision
- Velocity and heading can be simulated to plan accordingly
- You need to predict many seconds before collision in order to properly react
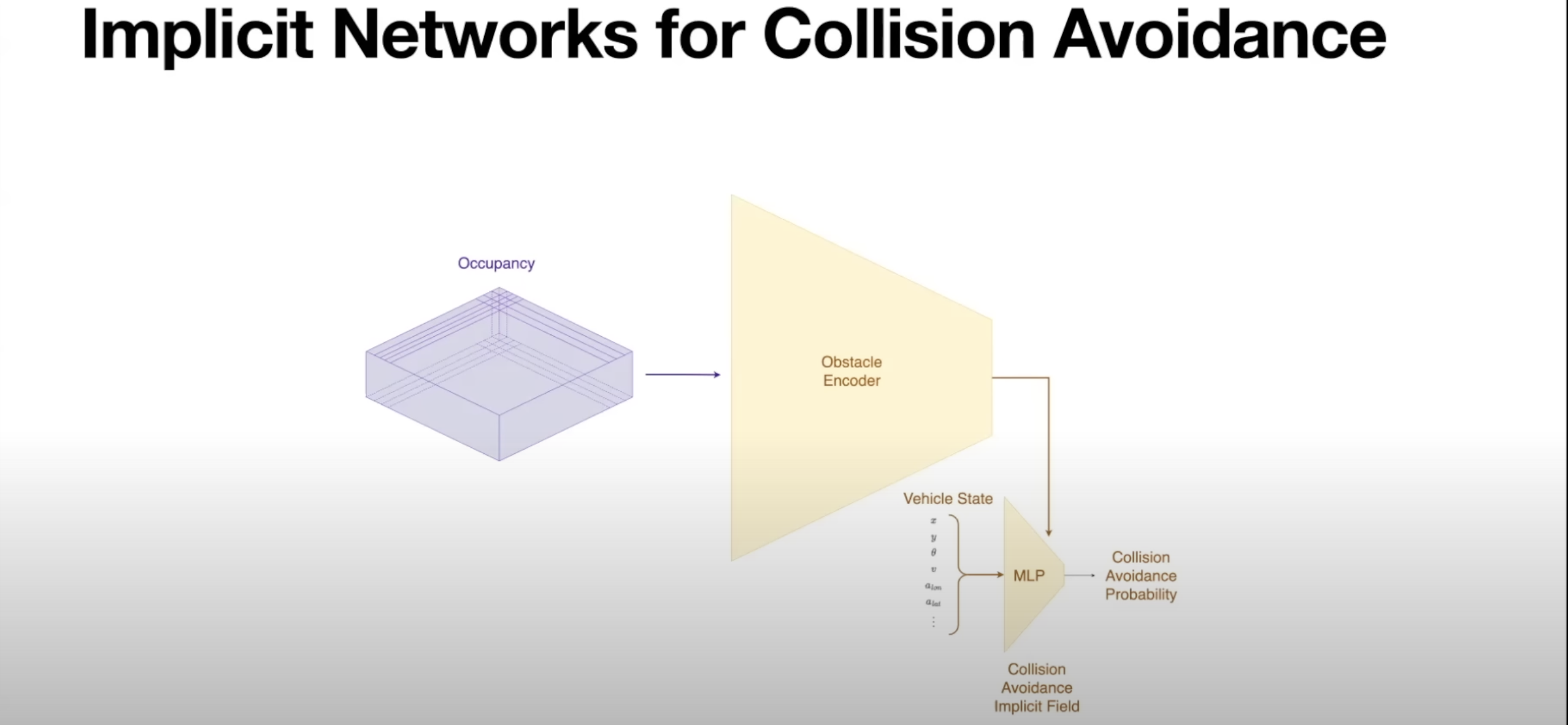
- Not enough time to produce in real-time so in the car we instead approximate with NNs, recent advent of implicit fields we are able to tap into the same work to produce implicit fields that encode obstacle avoidance
- Take occupancy from previous networks, encode to super compressed MLP which is a implicit representation of whether a collision is avoidable or not from any particular query state
- Gives some guarantees for collision avoidance for some time horizon
- Example: Is a collision avoidable for 2 seconds or 4 seconds ?
- Collision avoidance will have ability to hit brakes and steer around potential obstacle / collision
- Doing natively would take a couple of minutes to come up with a solution
- “Doing collision avoidance using networks enables us to quickly query for whether a collision is avoidable or not and then take actions that prevent collisions from happening”
- Summary
